Individual Differences in Learning to Localize Spatial Audio in VR
Problem
Personalizing HRTFs (the acoustic filter that shapes how each individual perceives spatial audio, based on their unique ear/head/torso anatomy) is expensive and hard to scale. A key question for VR audio product development is whether users actually need personalized HRTFs, or whether a well-designed generic HRTF combined with brief training is sufficient.
Approach
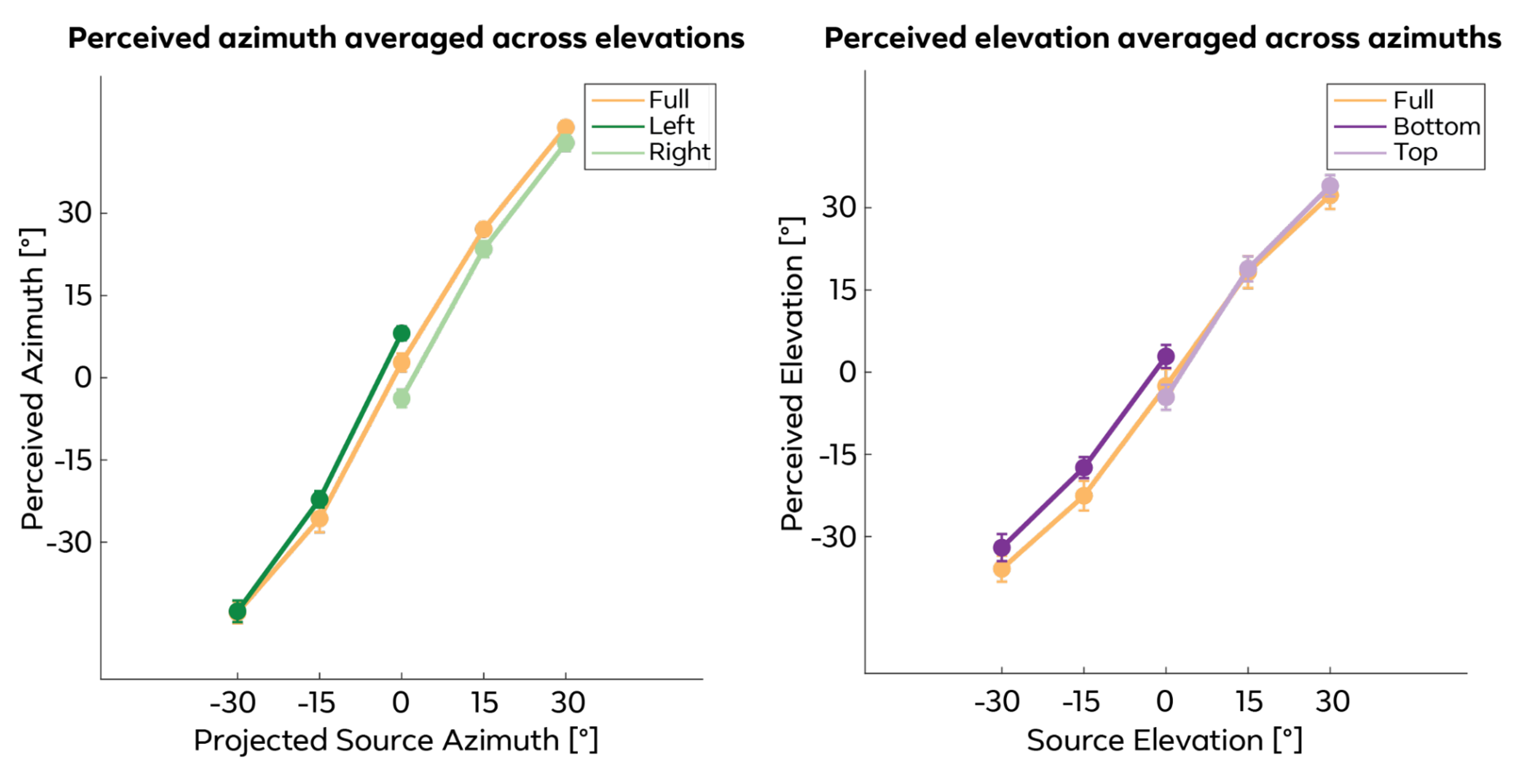
Our experiments on the Quest 3 headset compared naive listeners vs. those who completed a short training block with visual feedback, tested on both a generic and their own personalized HRTF. Localization accuracy was measured across azimuth, elevation, arc error, and front/back and top/bottom confusions.
Findings
Training had a large effect: among naive listeners, 58% were unable to localize spatial audio from all directions; after training, only 12% remained non-sensitive. Training reduced average arc error by ~17°. HRTF personalization had a statistically significant but small effect (~5° reduction in arc error), mainly improving elevation at extreme angles. These findings suggest that a generic HRTF combined with brief training may suffice for most VR applications — with implications for how onboarding should be designed and whether costly personalization pipelines are needed.